Cog Av Hearing - Research Outputs
Online Prototype Demo
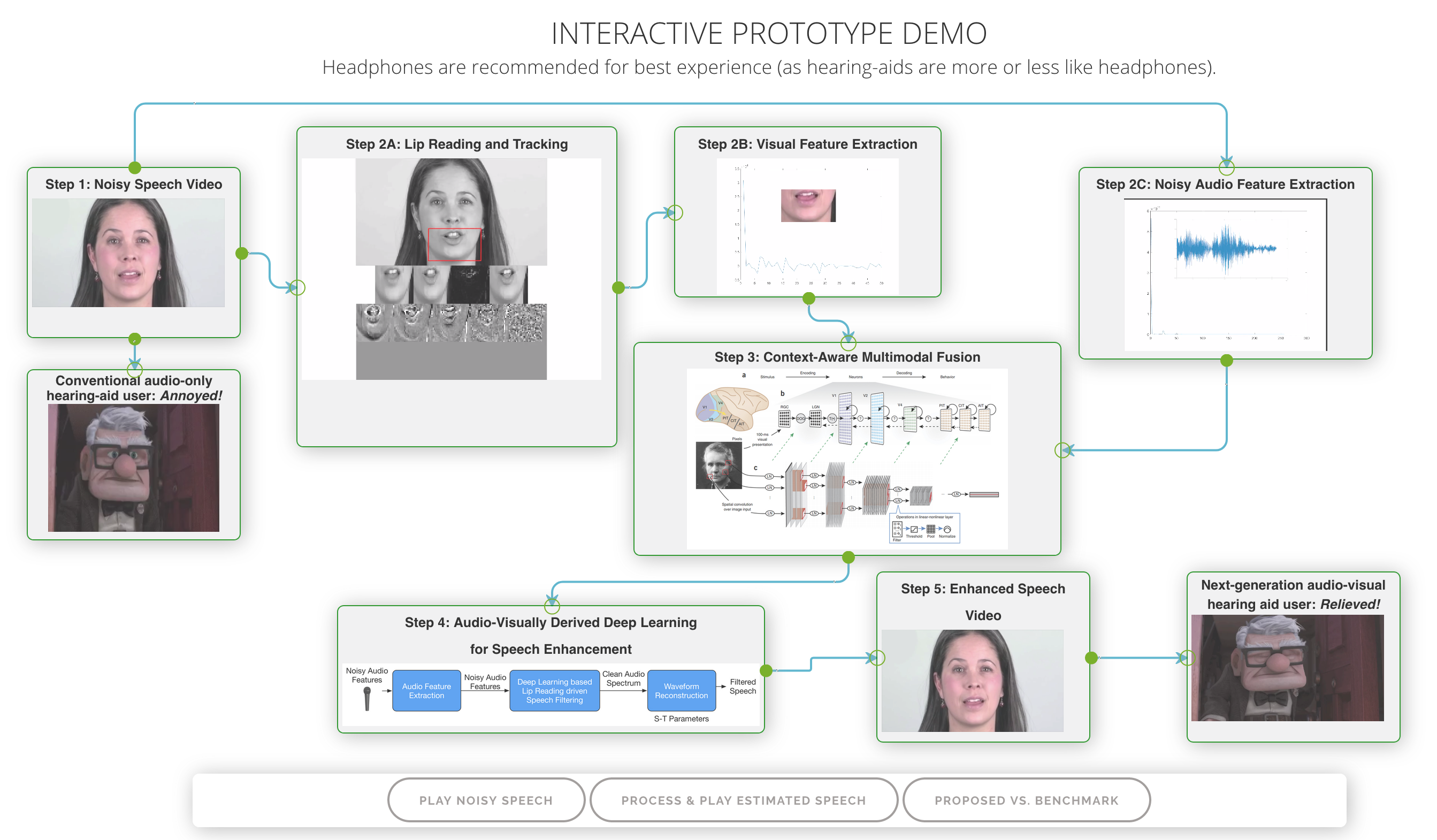
The multimodal hearing-aid demo is available at https://cogbid.github.io/cogavhearingdemo/ .
Remarkable progress and a proof of our hypothesis
Ongoing research has revealed that our proposed AV approach outperforms benchmark Audio-only approaches at low SNRs, and the improvement is statistically significant at the 95% confidence level for both white noise and benchmark ChiME noisy corpora. At high SNRs, the AV performance depends on the nature of the background noise. For the case of uncorrelated white noise, the audio-only method performs optimally. For the case of (spectro-temporally) correlated Chime2 noises, the AV performs comparably to Audio only. This shows that visual cues may be less helpful for AV noise 'filtering' based speech enhancement algorithms, at high SNRs (humans do relatively less lip reading at low levels of background noise too). The preliminary results have led us to propose the development of a more optimal, context-aware AV system that effectively accounts for different noisy/environmental conditions. To-date, we have developed a pilot, context-aware, deep learning driven lip-reading model for speech enhancement, that contextually learns and switches between AV cues with respect to different operating conditions, without requiring any SNR estimation. Comparative simulation results under dynamic real-world noisy environments, at different SNR levels, has demonstrated significant performance improvement of our proposed lip-reading model as compared to audio–only, visual-only, and state-of-the-art spectral subtraction, and linear minimum mean square error (LMMSE) based speech enhancement approaches.
2017 SICSA DemoFest
Ongoing EPSRC project outcomes were also presented at 2017 SICSA DemoFest - the largest industry-facing event of its kind organized by the national SFC funded SICSA pooling initiative, to showcase the very best of Informatics and Computing Science research from all of Scotland�s Universities. Our project received a very positive response from the attendee. In particular, we were invited for a collaboration opportunity with the EU H2020 funded project: MuMMER (MultiModal Mall Entertainment Robot), a four-year, EU-funded project with the overall goal of developing a humanoid robot (based on Softbank's Pepper platform) that can interact autonomously and naturally in dynamic environments of a public shopping mall, providing an engaging and entertaining experience to the general public. We hope our pioneering AV technology can help improve MuMMER�s speech recognition capabilities in very noisy environments, such as hotels, restaurants, bars, busy shopping malls etc.
AV-COGHEAR at Center for Robust Speech Systems, UTD, USA
Finally, the ongoing EPSRC AV-COGHEAR work was also presented, as part of an invited research visit (during November 2017) to the world-leading Center for Robust Speech Systems, at the University of Texas at Dallas. Discussions with Professor John Hansen, President of the International Speech Communication Association (ISCA) identified new endusers for our developed AV speech enhancement/recognition technology, including the US Navy (e.g. ear defenders for people controlling aircraft carriers deck operations), military (for officers not wearing earplugs), air traffic control towers (to improve communication and reduce risk of accidents) and cargo trains (to address driver distraction).
Geological Disaster Monitoring Workshop, Aug 2017
The EPSRC AV-COGHEAR work also received significant attention and appreciation from a large audience at the Geological Disaster Monitoring workshop, funded by the British Council and the National Natural Sciences Funding Council of China (NNSFC). Opportunities to exploit the potential of our disruptive technology in extremely noisy environments were identified e.g. in situations, where ear defenders are worn, such as emergency and disaster response and battlefield environments. Moreover, the exploitation of our developed AV speech enhancement technology in applications such as teleconferencing, where video signals could be used to filter and enhance acoustic signals arriving at the receiver-end, were also explored.
Demo/Poster Presentation:
Presented AV-COGHEAR Demo/Poster: Towards context-aware, cognitively-inspired multimodal hearing-aids and assistive technology at at Faculty Research Afternoon, Stirling, 18th April.
On-Going Work:
- Developed a new AV-ChiME3 corpus, by combining Grid Corpus clean audio/video with ChiME3 noises for a wide-range of SNRs ranging from -12 to 12dB.
- Speech recognition threshold (SRT) test for quantifying the intelligibility of speech in noise
- A novel real AV noisy speech corpus, which will serve as a new benchmark resource for the speech and hearing research community.
Visual Barcode Features
We are currently working on the development and application of cognitively inspired visual features, with some preliminary demo videos available. Please check the Visual Features page for more information.Visual Features
Project Datasets
We will develop and use a number of datasets during the course of this project for development and evaluation. Find out more details at our datasets page.Datasets
Presentations and Posters
British Society of Audiology Annual Conference (BSA 2016) - 25-27 April 2016
The conference was attended by project Research Fellow Andrew Abel, and a poster was presented, titled Audiovisual Speech Processing: Exploiting visual features for better noise reduction. A low resolution version of the poster is available for download .Poster Download Link