-
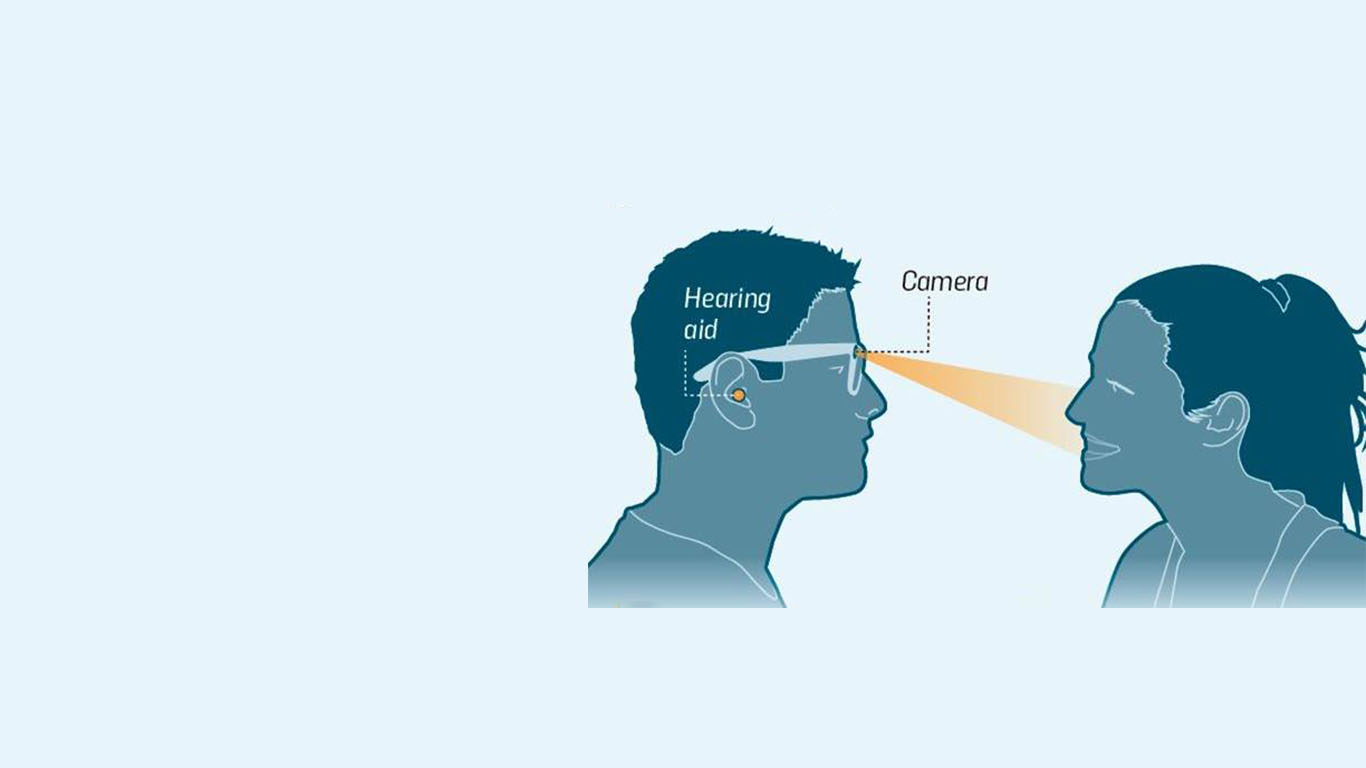
CHiME 3 AV Corpus
Know more
What is CHiME3 AV Corpus?
This new publicly available dataset is based on the benchmark audio-visual GRID corpus, which was originally developed by our project partners at Sheffield for speech perception and automatic speech recognition. The new dataset contains a range of joint audiovisual vectors, in the form of 2D-DCT visual features, and the equivalent audio log-filterbank vector. All visual vectors were extracted by tracking and cropping the lip region of a range of Grid videos (1000 videos from five speakers, giving a total of 5000 videos), and then transforming the region with 2D-DCT. The audio vector was extracted by windowing the audio signal, and transforming each frame into a log-filterbank vector. The visual signal was then interpolated to match the audio, and a number of large datasets were created, with the frames shuffled randomly to prevent bias, and with different pairings, including multiple visual frames to estimate a single audio frame (from one visual to one audio pairings, to 28 visual to one audio pairings).
This dataset will enable researchers to evaluate how well audio speech can be estimated using visual information only. Specifically, the application of novel speech enhancement algorithms (including those based on advanced machine learning), can be used to evaluate the potential of exploiting visual cues for speech enhancement.
Acknowledgements
This research was funded by the UK Engineering and Physical Sciences Research Council (EPSRC project AV-COGHEAR, EP/M026981/1)
Download
Please email cogbid {AT} gmail.com for getting access to the CHiME3 AV Corpus and cite the following article if you make use of the dataset.
Citing the corpus
@article{
adeel2020contextual,
title={Contextual deep learning-based audio-visual switching for speech enhancement in real-world environments},
author={Adeel, Ahsan and Gogate, Mandar and Hussain, Amir},
journal={Information Fusion},
volume={59},
pages={163--170},
year={2020},
publisher={Elsevier}
}
Adeel, Ahsan, Mandar Gogate, and Amir Hussain. "Contextual deep learning-based audio-visual switching for speech enhancement in real-world environments." Information Fusion 59 (2020): 163-170.